vscode ‘torch’ has no ‘xxx’ member
vscode User settings中加上
"python.linting.pylintArgs": [
"–errors-only",
"–generated-members=numpy.* ,torch.* ,cv2.* , cv.*",
]
Soar360@live.com
GBPduHjWfJU1mZqcPM3BikjYKF6xKhlKIys3i1MU2eJHqWGImDHzWdD6xhMNLGVpbP2M5SN6bnxn2kSE8qHqNY5QaaRxmO3YSMHxlv2EYpjdwLcPwfeTG7kUdnhKE0vVy4RidP6Y2wZ0q74f47fzsZo45JE2hfQBFi2O9Jldjp1mW8HUpTtLA2a5/sQytXJUQl/QKO0jUQY4pa5CCx20sV1ClOTZtAGngSOJtIOFXK599sBr5aIEFyH0K7H4BoNMiiDMnxt1rD8Vb/ikJdhGMMQr0R4B+L3nWU97eaVPTRKfWGDE8/eAgKzpGwrQQoDh+nzX1xoVQ8NAuH+s4UcSeQ==
语言虽然看起来是一个序列,实际上内部是有复杂的层次结构的,这也是NLP的难点所在。复杂的层次结构,意味着序列即使看起来相同,也可能因为内部层次结构的不同而有语义的差别。
在斯坦福CS224n上提到了这样的一个例子:
The police killed the man with a knife.
这个句子,可以有两种理解:
上面两种解释对应的句法树分别是这样的:
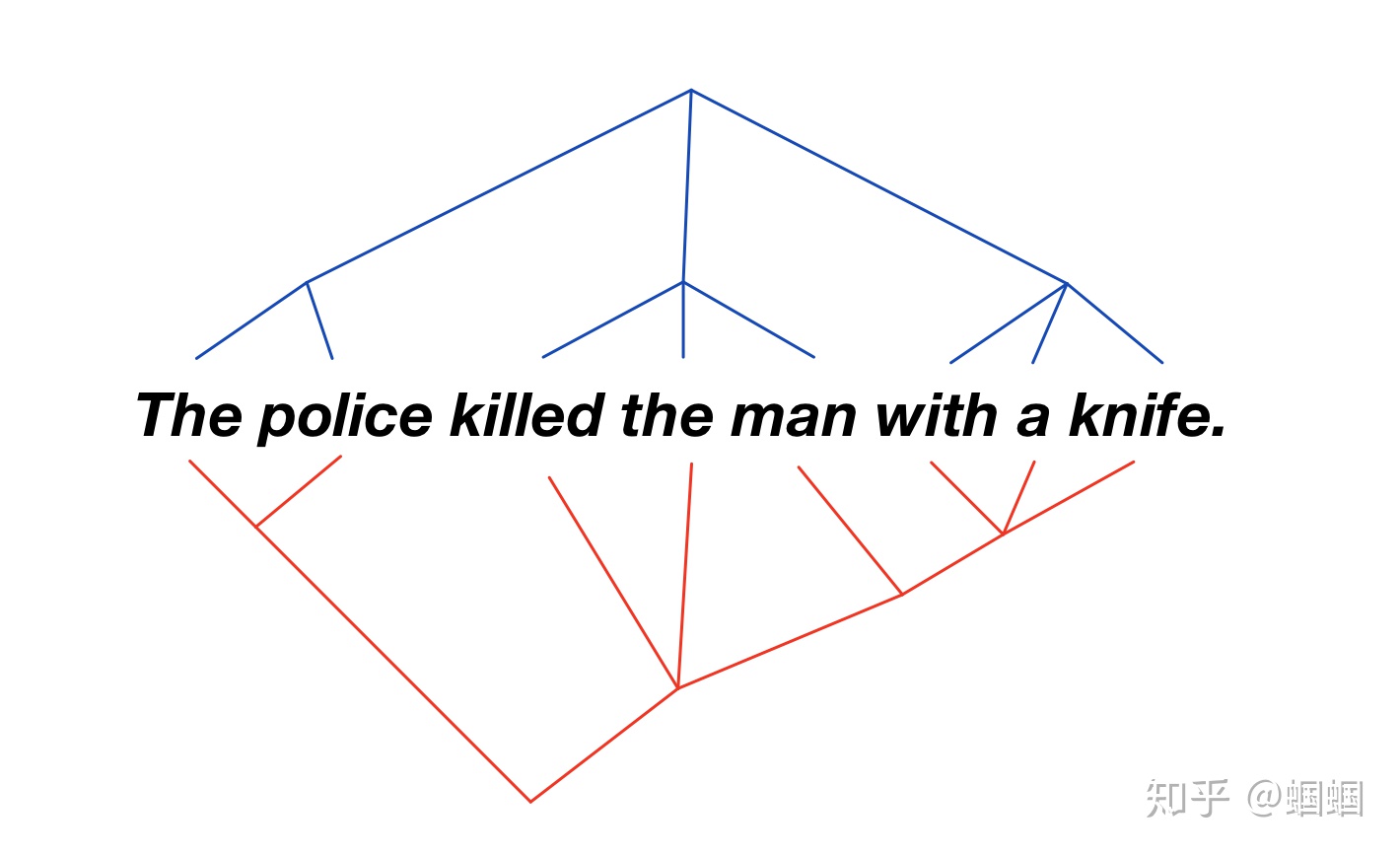
序列看起来一样,但是由于内部的层级结构不一样会导致不同的语义理解
当用LSTM为语言序列编码Encode的时候,由于LSTM单纯认为语言是一个序列,忽略了语言内部的语法树的层级结构,因此其无法解决上面相同序列,不同语义的问题。
本文提出ON-LSTM(Ordered Neurons - LSTM),通过重新设计LSTM递归的cell的cell states的更新方式及策略,实现将语法树的层级结构融合进LSTM编码器中,解决上述问题。
LSTM主要由三个特殊的门(gate)结构组成:遗忘门、输入门、输出门
具体的公式如下:
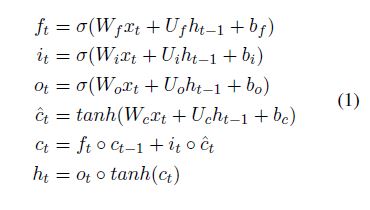
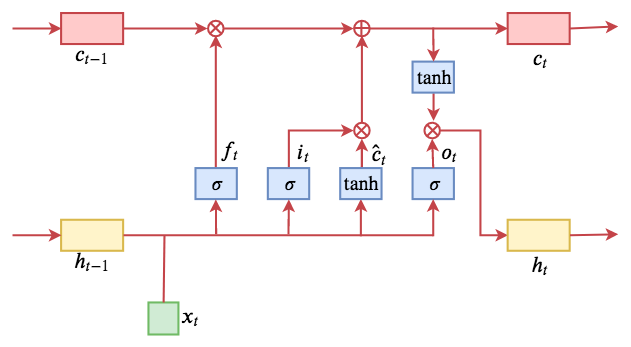
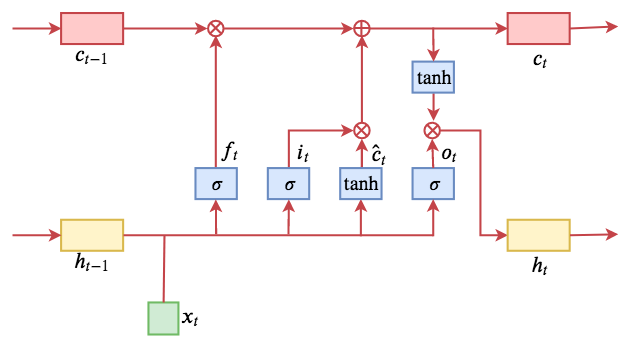
示意图如下:
论文中一直是从神经元排序的角度解释的,对我个人来说,很难理解,故下文按照cell state的角度理解。
LSTM的核心就是cell state:信息在cell state这个传送带上流动,伴随着一些简单的线性变换,乘和加,分别由“遗忘门”和“输入门”来控制cell state的信息更新。
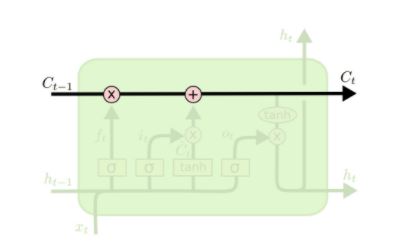
这样存在一个问题:
每次更新,cell state这个向量的每一维都会更新
信息流就是存在于这个cell state中,如果希望模型可以刻画出语言的结构信息,也就意味着这个cell state中要隐含着层次结构的信息。
所以作者希望,能够让这个cell state的不同维度,对应到语言的不同层级上,让不同的层级使用不一样的方式进行更新,具体来说就是层次越高的更新越少。这样的话,cell state就包含了层次信息了。
作者的例子:
假设我们有一个很简单的句子,三个词组成[x1,x2,x3],有三个层次,用下图的最左边的图表示,分别是句子(S)、短语(NP,VP)、词(N,V)。我们希望cell state中也可以有对应的三个层次,层次就体现在不同的更新频率上。

层次越高的,自然其信息应该保留的时间更久,所以其更新频率应该越低。上图的最右边是三个词分别对应的cell states。颜色越深代表更新频率越高。
这样,就相当于给cell states加了一个顺序,从某种意义上讲也相当于是给LSTM的神经元加了顺序,因此作者称这种结构是Ordered-Neurons,对应的LSTM称为ON-LSTM。所以并不是真的给神经元排序。
接下来的问题:
上面给cell states这样分区间,是因为我们提前知道了句子的结构,但我们真正使用LSTM进行建模、训练的时候,是不知道语言的真实层次的,除非你先把每个句子都解析成语法树,再显式加入到LSTM中的,但是这种方法不仅开销大,而且不一定可靠,所以我们需要设计一种结构,让模型可以学习到如何给cell state去分区。
为了实现区间的划分,模型用到了两个整数 $l_{his}$ 和 $l_{now}$,它们分别用来表示历史信息的最低等级 和 当前信息的最高等级
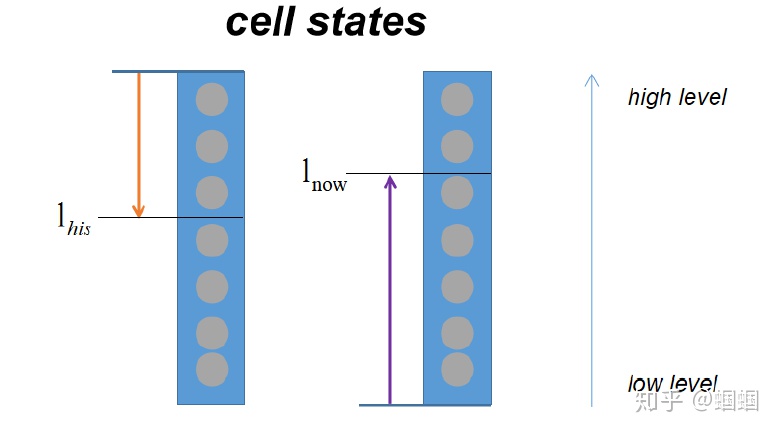
总体上,就包含以下两种情况:
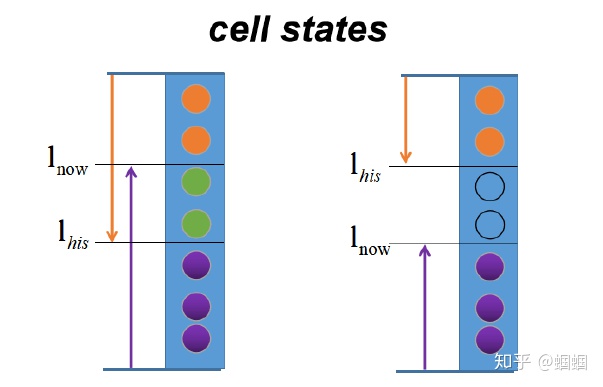
$l_{his} < l_{now}$ ,有重叠交汇部分:
$l_{his} > l_{now}$ ,无重叠交汇部分:
其实该模型认为高层次的语法信息主要是来自于历史信息,而低层次的主要来自当前输入信息,而这也比较符合人们的直观印象,对于一个新的输入,它对于语法信息的影响往往局限于一个较低的层次,高层次的信息(如句子或者短语信息)仍然来自于历史信息,只有当一个句子或者短语完结的时候,历史信息的影响变小,这时新的输入才有可能影响较高语法层次的信息。而这样也就使得高语法层次的信息的更新频率较低,大多时候是保持不变,而低语法层次的信息则随着当前的输入一直变化。
把$l_{his}、 l_{now}$转化为向量
定义累加函数
因此,
由于,上面这种分为0段和1段的形式,都是整数,这样函数不可导,无法训练,所以需要做一下软化,即用softmax函数处理一下。
定义 $cummax(X) = cumsum(softmax(X))$
综上,引入两个门(gate)结构:master forget($\tilde{f_t}$)、master input($\tilde{i_t}$)。
具体计算公式如下:
整体计算流程如下:
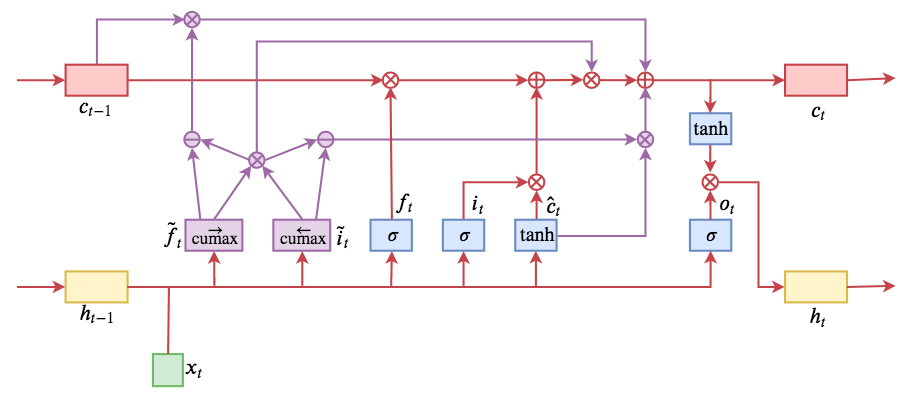
通常隐层神经元的数目都比较大,而实际中语法的层数远远达不到这个数字,因此对于$\tilde{f_t}$和$\tilde{i_t}$而言,其实不需要那么多的维数,这样会导致需要学习的参数量过多,但是 $\circ$ 要求它们的维数必须这么大,因此我们可以构造一个维数为$D_m = D / c$ 的向量,其中D为隐层神经元的维数,然后在将其扩充为D维向量,例如D=6,c=3,先构造一个向量[0.2, 0.8] ,然后将其扩充为 [0.2, 0.2, 0.2, 0.8, 0.8, 0.8] 。
该ON-LSTM模型从语法结构的角度出发,根据语法层次对cell states进行有序排列,再按照语法层次的不同实行不同的更新规则,从而实现对于较高语法层次信息的保留,这样对于语言模型等任务无疑是很有利的。另外,利用该模型还能够较好地从句子中无监督地提取出语法结构,而这也是该模型的一大亮点。
[1] ORDERED NEURONS: INTEGRATING TREE STRUCTURES INTO RECURRENT NEURAL NETWORKS
本文研究了关系抽取(Re)的任务,目的是识别文本中提到的两个实体之间的语义关系。 在Re的深度学习模型中,整合输入句子的依存树中的句法结构是有益的。
在这种模型中,依赖树经常被用来直接构造网络结构或获得单词对之间的依赖关系,以此通过多任务学习将句法信息注入模型中。
这些方法的主要问题是训练数据中缺乏超越句法结构的泛化,或者未能捕捉词对于RE的句法重要性。
为了克服这些问题,我们提出了一种新的Re深度学习模型,该模型使用依赖树提取单词的基于句法的重要性得分,作为树的向量表示,以将句法信息注入具有更大泛化性的模型中。
特别是,我们利用有序神经元长短期记忆网络(ON-LSTM)来推断句子中每个单词的基于模型的重要性得分,然后对其进行调整,使其与基于句法的分数保持一致,从而实现句法信息注入。
我们进行了广泛的实验来证明所提出的方法的有效性,从而在三个基准数据集上取得了SOTA性能。
最近对RE的研究集中在深度学习上,以开发从文本数据中自动生成句子向量表示的方法。在这些最近的研究中,值得注意的是,输入句子的句法树(即依存树)可以为深度学习模型提供有效的信息,从而得到SOTA性能
特别是,以前的RE深度学习模型大多都利用句法树中呈现的单词连接来构造网络结构(例如,依存树上的图卷积神经网络(GCN))。不幸的是,这些模型由于训练数据的树结构可能与测试数据中的树结构有很大的不同而导致泛化性较差,即模型过拟合于训练数据的句法树结构。这一问题在跨领域RE时,尤为明显。
为克服这一问题,总体策略是获得更一般的句法树向量表示,这些嵌入向量可用来将句法信息注入到深度学习模型中,以获得更好的泛化效果。
2019年 Veyseh等人给出了RE的一般树表示,其中依存树被分解为句子中单词之间的依赖关系集(即边),称为基于边的表示。然后,在多任务学习框架中使用这些依赖关系,来同时预测两个实体间的关系和输入句子中单词对之间的依赖关系。
基于边的表示的主要缺点是它只捕获单词之间的成对(局部)连接,而完全忽略了单词在句子中对RE问题的整体(全局)重要性,特别是,在RE的关系预测过程中,给定句子中的某些单词可能比其他单词包含更有用的信息,并且这个句子的依存树可以帮助更好地识别那些重要的单词,并为它们分配更高的重要性得分(即在两个实体之间沿最短依赖路径选择单词)
在本文中,我们提出从依存树中获得句子中每个单词的重要性得分(称为基于句法的重要性得分 syntax-based importance scores),这将作为依存树的一般向量表示,以将句法信息注入RE深度学习模型中。
如何在RE深度学习模型中使用基于句法的重要性得分?
为了实现上述想法,本文首次采用了ON-LSTM(Ordered-Neuron Long Short-Term Momory Networks)计算单词的model-based importance scores。
ON-LSTM相较于LSTM新填了2个门(gate)结构:
ON-LSTM局限:
master gates 和 model-based importance scores 仅依赖于当前词本身及其左上下文(先前时刻隐状态)
为了更有效利用整个句子的信息,本文提出先生成整个句子的向量表示,并把其作为每个单词计算其重要性得分的输入
为了进一步改善深度学习模型的编码能力,以学习到更好的特征向量,本文引入一种新的归纳偏置:
使 基于两个实体间的最短依赖路径的特征向量 和 基于整个句子的特征向量 的相似度尽可能高
该归纳偏置基于以下直觉:句子中两个实体的语义关系可以从整个句子或者最短依赖路径中推断出来。
本文模型主要分为三大组件:
三部分的拼接:
公式如下:
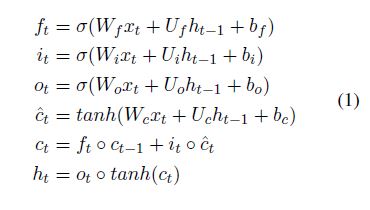
计算流程图如下:
为了将依存树中的句法结构融合进LSTM,引入两个门(gate):master forget($\tilde{f_t}$)、 master input($\tilde{i_t}$)
首先定义累加函数
定义数值软化函数 $cummax(X) = cumsum(softmax(X))$
具体计算公式如下:
整体计算流程如下:
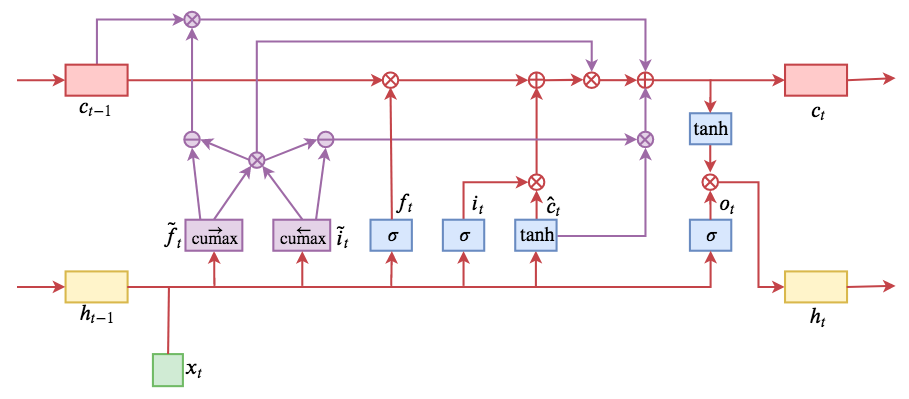
$\tilde{f_t}$和$\tilde{i_t}$的输出分别从0递增到1、从1递减至0,且都可以分为两个段(近0段、近1段),其中近1段可以理解为当前时间步处于活跃状态的cell states中的神经元/维度。详见2
因此,本文利用近1段,即处于活跃态的维度的个数计算model-based scores。
master forget的值:
model-based score:
ON-LSTM引入句子上下文信息
用下述$x’_t$代替mater gates计算中的$x_t$
首先,计算syntax-based importance score ($syn_t$):
经过上述计算,位于最短依存路径DP上的单词的重要性得分均为T, 而其他单词,距离DP越远得分越低。
该syntax-based score可以看作是原始依存树的泛化(relaxd)版,可以避免模型对训练数据语法结构的过拟合
Syntax-Model Consistency的思路可以理解为:
利用syntax-based score为model-based score提供监督信号,通过KL散度定义loss
计算公式如下:
最大化基于句子整体的特征向量和基于最短依存路径的特征向量的相似度
首先计算句子$X$和最短依存路径$DP$的特征向量表示$R_X$、$R_{DP}$
定义损失函数:
用于RE预测的全部特征向量为:
损失函数定义:
[1].Exploiting the Syntax-Model Consistency for Neural Relation Extraction
[2].ORDERED NEURONS:INTEGRATING TREE STRUCTURES INTO RECURRENT NEURAL NETWORKS
scrapy startproject tutorial 创建名为tutorial的项目
Items.py:
import scrapy
class DmozItem(scrapy.Item):
title = scrapy.Field()
link = scrapy.Field()
desc = scrapy.Field()
tutorial/spiders/下创建 dmoz_spider.py:
必须继承scrapy.Spider类;定义 name、start_urls、parse()
import scrapy
class DmozSpider(scrapy.spiders.Spider):
name = "dmoz"
allowed_domains = ["dmoz.org"]
start_urls = [
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
"http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)
首先,进入项目根目录
scrapy crawl dmoz
for sel in response.xpath('//ul/li'):
title = sel.xpath('a/text()').extract()
link = sel.xpath('a/@href').extract()
desc = sel.xpath('text()').extract()
print title, link, desc
from tutorial.items import DmozItem
def parse(self, response):
for sel in response.xpath('//ul/li'):
item = TutorialItem()
item['title'] = sel.xpath('a/text()').extract()
item['link'] = sel.xpath('a/@href').extract()
item['desc'] = sel.xpath('text()').extract()
yield item
scrapy crawl dmoz -o items.json
linux最优秀的地方,就在于多用户、多任务环境
文件所有者
用户组
其他人
root用户极其特殊,拥有最高权限
/etc/passwd
/etc/shadow
/etc/group
对数据安全性及系统保护有重要意义
ls -al
显示当前目录下所有文件及目录的详细信息
-a 显示所有,包括隐藏文件(文件名以.开始的)
-l 显示详细信息
ls -al 输出7列信息
第一列表示这个文件的类型与权限(permission),共计10个字符
第一个字符表示文件类型
剩下九个每3个一组,分别为“文件所有者”、“同用户组”、“其他非本用户组”的权限,均含有“rwx”三个参数组合
第二列表示有多少个文件名连接到此节点(i-node)
第六列表示这个文件的创建日期或者最近修改日期
第七列表示该文件名
chown
chmod
数字类型
符号类型
文件
目录
w-更改该目录结构列表的权限,与文件名变动有关
x-能否进入该目录作为工作目录
普通文件
目录
连接文件
一个文件能不能被linux执行,与它的第一列的10个属性有关,与文件名后缀一点关系没有
Linux默认情况会提供6个terminal来让用户登录,切换的方式是:[Ctrl]+[Alt]+[F1]~[F6],用户名密码登录,exit注销
这六个终端界面命名为 tty1~tty6,[Ctrl]+[Alt]+[F7]返回图形界面tty7
若想要更改linux默认的登录模式,需要修改 /etc/inittab,下次重启生效
ls
ls -al ~
ls -a -l ~
echo $LANG
LANG=en_US
date
cal
bc
[Tab]
[Ctrl] + c
[Ctrl] + d
诸如“DATE(1)”中的数字的意义(1-9),常用数字如下:
man page 主要内容包括:
man page 常用按键
高阶命令
查找与指定命令或数据有关的man page文件
查找包含指定关键字的man page文件
info与man的用途差不多
info page将文件数据拆成一个一个的段落,每个段落用自己的页面撰写,并且每个页面有“超链接”来跳到不同的页面中,每个独立的页面称为节点(Node)
info page是只有linux才有的产物,必须按照info page的格式撰写求助文件才能具有info page的功能,info page的文件放置于/usr/share/info/目录中
非info page格式的文件也能用info显示,只不过显示效果与man相同
第一行
Menu
上述命令不区分大小写字母
进入nano
离开nano
查询字符串
^表示[Ctrl]
M表示[Alt]
命令
目的
shutdown可以完成如下工作:
可以自由选择关机模式:关机、重启、单用户操作模式
可以设置关机时间
可以自定义关机消息
可以仅发出警告消息,不关机或重启
可以选择是否要用fsck检查文件系统
init 0也可以关机
SATA/USB接口的磁盘根本没有一定的顺序
磁盘的组成
所谓的分区只是针对64B的分区表进行设置
硬盘默认的分区表仅能写入四组分区信息,这四个分区信息称为主分区(primary)或扩展分区(extended)
扩展分区最多只能有一个
分区最小的单位是柱面
扩展分区继续切分的分区,叫做逻辑分区,逻辑分区的设备名称号码由5开始,1-4是保留给主分区或者扩展分区使用的,SATA硬盘最多11个逻辑分区(5-15)
能够被格式化后作为数据访问的分区为主分区与逻辑分区,扩展分区无法格式化
引导加载程序可以安装在MBR,也可安装于每个分区的引导扇区(boot sector)
Linux的所有数据都是以文件的形态呈现的
目录树结构
可以把/home、/usr、/boot、/var都单独分区